Ivy as a Transpiler#
Here, we explain the Ivy’s source-to-source transpiler and computational graph tracer, and the roles they play.
Supported Frameworks
Framework |
Source |
Target |
|
|---|---|---|---|
PyTorch |
✅ |
🚧 |
|
TensorFlow |
🚧 |
✅ |
|
JAX |
🚧 |
✅ |
|
NumPy |
🚧 |
✅ |
Source-to-Source Transpiler ✅#
Ivy’s source-to-source transpiler enables seamless conversion of code between different machine learning frameworks.
Let’s have a look at a brief example:
import ivy
import tensorflow as tf
import torch
class Network(torch.nn.Module):
def __init__(self):
super().__init__()
self._linear = torch.nn.Linear(3, 3)
def forward(self, x):
return self._linear(x)
TFNetwork = ivy.transpile(Network, source="torch", target="tensorflow")
x = tf.convert_to_tensor([1., 2., 3.])
net = TFNetwork()
net(x)
The transpiled TensorFlow class is immediately available for use after the ivy.transpile call, as shown in this example, but the generated source code is also saved into the ivy_transpiled_outputs/ directory, meaning you can edit the source code manually after the fact, or use it just as if the model had been originally written in TensorFlow.
Graph Tracer ✅#
The tracer extracts a computational graph of functions from any given framework functional API. The dependency graph for this process looks like this:

Let’s look at a few examples, and observe the traced graph of the Ivy code against the native backend code. First, let’s set our desired backend as PyTorch. When we trace the three functions below, despite the fact that each has a different mix of Ivy and PyTorch code, they all trace to the same graph:
def pure_ivy(x):
y = ivy.mean(x)
z = ivy.sum(x)
f = ivy.var(y)
k = ivy.cos(z)
m = ivy.sin(f)
o = ivy.tan(y)
return ivy.concatenate(
[k, m, o], -1)
# input
x = ivy.array([[1., 2., 3.]])
# create graph
graph = ivy.trace_graph(
pure_ivy, x)
# call graph
ret = graph(x)
|
def pure_torch(x):
y = torch.mean(x)
z = torch.sum(x)
f = torch.var(y)
k = torch.cos(z)
m = torch.sin(f)
o = torch.tan(y)
return torch.cat(
[k, m, o], -1)
# input
x = torch.tensor([[1., 2., 3.]])
# create graph
graph = ivy.trace_graph(
pure_torch, x)
# call graph
ret = graph(x)
|
def mix(x):
y = ivy.mean(x)
z = torch.sum(x)
f = ivy.var(y)
k = torch.cos(z)
m = ivy.sin(f)
o = torch.tan(y)
return ivy.concatenate(
[k, m, o], -1)
# input
x = ivy.array([[1., 2., 3.]])
# create graph
graph = ivy.trace_graph(
mix, x)
# call graph
ret = graph(x)
|

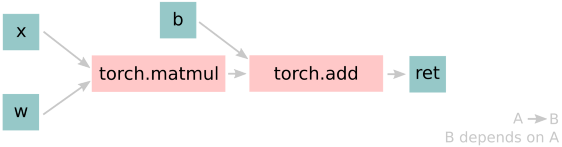
For all existing ML frameworks, the functional API is the backbone that underpins all higher level functions and classes. This means that under the hood, any code can be expressed as a composition of ops in the functional API. The same is true for Ivy. Therefore, when compiling the graph with Ivy, any higher-level classes or extra code which does not directly contribute towards the computation graph is excluded. For example, the following 3 pieces of code all result in the exact same computation graph when traced as shown:
class Network(ivy.module)
def __init__(self):
self._layer = ivy.Linear(3, 3)
super().__init__()
def _forward(self, x):
return self._layer(x)
# build network
net = Network()
# input
x = ivy.array([1., 2., 3.])
# trace graph
net.trace_graph(x)
# execute graph
net(x)
|
def clean(x, w, b):
return w*x + b
# input
x = ivy.array([1., 2., 3.])
w = ivy.random_uniform(
-1, 1, (3, 3))
b = ivy.zeros((3,))
# trace graph
graph = ivy.trace_graph(
clean, x, w, b)
# execute graph
graph(x, w, b)
|
def unclean(x, w, b):
y = b + w + x
print('message')
wx = w * x
ret = wx + b
temp = y * wx
return ret
# input
x = ivy.array([1., 2., 3.])
w = ivy.random_uniform(
-1, 1, (3, 3))
b = ivy.zeros((3,))
# trace graph
graph = ivy.trace_graph(
unclean, x, w, b)
# execute graph
graph(x, w, b)
|
This tracing is not restricted to just PyTorch. Let’s take another example, but trace to Tensorflow, NumPy, and JAX:
def ivy_func(x, y):
w = ivy.diag(x)
z = ivy.matmul(w, y)
return z
# input
x = ivy.array([[1., 2., 3.]])
y = ivy.array([[2., 3., 4.]])
# create graph
graph = ivy.trace_graph(
ivy_func, x, y)
# call graph
ret = graph(x, y)
|
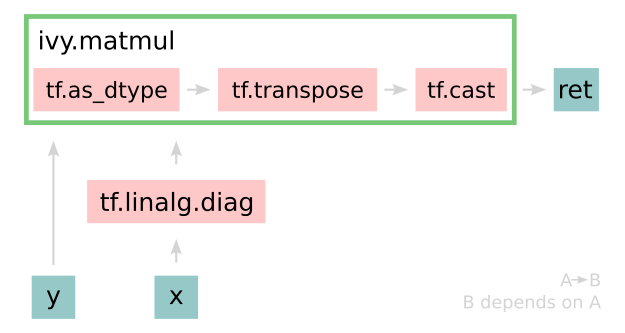
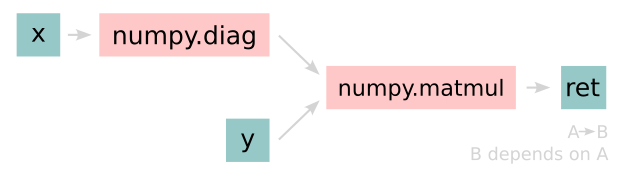
Converting this code to a graph, we get a slightly different graph for each backend:
Tensorflow:
Numpy:
Jax:
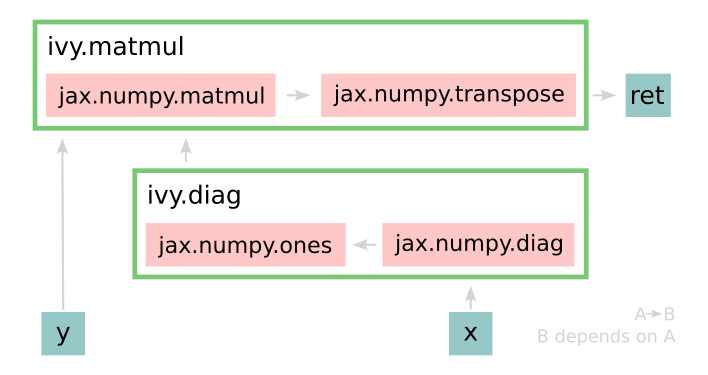
The example above further emphasizes that the tracer creates a computation graph consisting of backend functions, not Ivy functions. Specifically, the same Ivy code is traced to different graphs depending on the selected backend. However, when compiling native framework code, we are only able to trace a graph for that same framework. For example, we cannot take torch code and trace this into tensorflow code. However, we can transpile torch code into tensorflow code (see Ivy as a Transpiler for more details).
The tracer is not a compiler and does not compile to C++, CUDA, or any other lower level language.
It simply traces the backend functional methods in the graph, stores this graph, and then efficiently traverses this graph at execution time, all in Python.
Compiling to lower level languages (C++, CUDA, TorchScript etc.) is supported for most backend frameworks via ivy.compile(), which wraps backend-specific compilation code, for example:
# ivy/functional/backends/tensorflow/compilation.py
compile = lambda fn, dynamic=True, example_inputs=None,\
static_argnums=None, static_argnames=None:\
tf.function(fn)
# ivy/functional/backends/torch/compilation.py
def compile(fn, dynamic=True, example_inputs=None,
static_argnums=None, static_argnames=None):
if dynamic:
return torch.jit.script(fn)
return torch.jit.trace(fn, example_inputs)
# ivy/functional/backends/jax/compilation.py
compile = lambda fn, dynamic=True, example_inputs=None,\
static_argnums=None, static_argnames=None:\
jax.jit(fn, static_argnums=static_argnums,
static_argnames=static_argnames)
Therefore, the backend code can always be run with maximal efficiency by compiling into an efficient low-level backend-specific computation graph.
Round Up
Hopefully, this has explained how, with the addition of backend-specific frontends, Ivy will be able to easily convert code between different ML frameworks 🙂 works in progress, as indicated by the construction signs 🚧. This is in keeping with the rest of the documentation.
Please reach out on discord if you have any questions!